商业银行核心系统基于Dell EMC 全闪存储的双活建设及智能监控实践
【文章摘要】 本文介绍了 银行 在建设新核心系统过程中基础架构室所做的主要工作:双活数据中心的建设。主要包括技术选型、设备选型、双活策略等,概括性的描述了网络、计算、存储、数据库如何在双活数据中心中部署及切换。重点介绍了其中的核心存储SRDF/METRO的技术特点和切换策略,以及为该技术量身定制的监控方案。
1. 项目背景
我行上一代核心开发于十多年以前,当时的银行信息化程度与现在不可同日而语,很多功能现在看来存在严重缺陷,无法适应业务创新和互联网业务的开展,远远落后于主流银行的核心系统。为了适应银行业当前激烈的竞争压力,抓住银行业数字化转型的机遇,我行在2年前上线了新一代核心系统,并以新核心建设为契机,对企业架构进行了演进和提升,在业务架构、数据架构、技术架构等方面进行了全面的提升,将我行从银行系统化阶段提升至信息化银行阶段。基础架构作为技术架构的一部分,主要是 放弃了主流的同城主备架构,采用了领先的双活架构,真正实现了7*24小时不间断服务 。
2. 需求分析
基础架构的主要需求就是结合核心系统的特点,实现同城双活,两个数据中心同时承载业务。当某个数据中心出现大面积故障或者灾害时,可以顺利的切换到另外一个数据中心,保证业务不出现重大故障。难点主要有:
1、 新核心双活数据中心的架构规划,技术方向和产品的选型
2、 对已有的系统的全面梳理将老系统迁移到新架构
3、 全面的测试,需要尽量多的覆盖可能的场景
4、 切换方案的制定和演练
5、 双活存储的监控
3. 总体架构
新核心系统软件上实现了基于Java的微服务架构。基础架构方面并没有太多特殊需求,其中核心采用了分布式架构,多达30多台应用服务器,其他外围系统大部分采用2+2方式部署,数据库采用2+2的4节点RAC及1节点ADG的架构。
基于这种设计原则,网络采用了业界流行的SDN网络架构,在两个数据中心各部署2台GTM,实现基于DNS的全局负载均衡,请求进入GTM选择的数据中心后,通过负载均衡访问内部系统,各个系统之间访问通过GTM策略只访问所在中心的应用服务器,不跨数据中心访问。如果某个数据中心2个应用服务器均不可用,则负载均衡服务失败,同时通知GTM不再响应本数据中心IP给DNS请求。
计算绝大部分采用了基于x86的VMware虚拟化平台,基于以前使用刀片服务器的经验,考虑当前服务器的CPU越来越强,内存越来越大,而刀片的网络管理会造成管理职责不清晰,为了减小故障域、简化拓扑、降低维护难度,我们放弃了使用刀片服务器,选择全部使用机架式服务器。从可靠性和性能方面的考虑,部分关键数据库采用了PowerVM虚拟机,在存储及网络上也给予了特殊的资源分配,例如专用的存储前端口、专用的网络交换机。 我们的架构是两地三中心架构。同城两中心存储则分为双活和单活两部分,应用及操作系统使用单活,数据库使用的ASM盘则采用Dell EMC PowerMAX with SRDF Metro 双活存储,ADG使用单活存储。我们的异地灾备则是通过 ADG 所在的 Dell EMC 存储 +RecoverPoint来实现。
存储则分为双活和单活两部分,应用及操作系统使用单活,数据库使用的ASM盘则采用双活存储,ADG使用单活存储。
应用数据的共享采用的NAS双活的架构,由于NFS协议本身的限制,并不是真真的双活,依然是主备方式,考虑到应用对于数据共享的性能延迟要求并不高,业内也并没有更好的成熟解决方案可选择,所以并没有选择更激进的方案。
数据库主要是采用了4节点Oracle Rac的方式,考虑业内常用的方案,并且我行已经有多年使用vplex作为双活存储网关来为存储提供双活存储的经验,所以没有采用oracle推荐的ASM同步数据的方式,而是采用双活存储同步数据的方案。经过对常用应用的数据模型分析,绝大部分性能问题并不是来自于数据库的IO,而是系统自身设计和优化的问题,为了减少争用和存储不稳定对数据库造成不可预知的问题,4节点RAC并没有同时支持读写,而是采用了1主3备的方式。未来在技术成熟的情况下,可以随时切换为4节点RAC同时读写,或者是读写分离模式。
4. 双活存储设备选型
作为核心系统数据库的存储,还是考虑采用当前主流的集中式FC SAN块存储,选型主要从以下几方面考虑:
1、目前SSD已经成为主流,无论是可靠性、性能、能耗、故障率等方面对机械硬盘有明显优势。且在综合考虑去重和压缩的功能,成本已经有与传统机械盘相差无几。
2、全闪存储具有诸多基于SSD硬盘的特性,例如去重压缩等,可以发挥SSD存储的最大优势,所以在存储的选择上,全闪存储优于混合存储。
3、必须是真双活,可以支持更灵活的需求,当前业内能够实现真双活的存储并不多。
4、优选存储双活,而非外挂双活网关。网关类方案会成为全闪的性能瓶颈、带来更多的故障点、配置更复杂,部分存储特性无法使用。
5、必须是在业内具有大量成功案例的产品
存储的标杆厂商Dell EMC, 最开始的同城解决方案SRDF/S是一个主备方案 ,并不能实现双活。Dell EMC的第一个双活方案是通过vplex网关来实现的,我们是第1批用户,是我行灾备项目的重要组成部分。总体来说还是比较稳定,但性能偏弱、难以升级、配置复杂。而SRDF/Metro是更新的解决方案,是构建于Vmax/Powermax高端存储之上的双活方案,性能方面有高端存储充足的计算资源作为保证, 可靠性方面又有VPLEX和SRDF多年的经验作为保证,已经在金融行业有大量成功案例。最终我们选择了DellEMC VMAX250F存储作为核心系统的双活存储。
5. 双活设计
5.1. SRDF复制方式
SRDF是Dell EMC symmetrix产品的远程容灾解决方案,主要通过在远程建立镜像为源生产提供容灾保护。SRDF有同步和异步两种同步模式,作为双活数据中心,自然是选择同步模式:
① 主机将接收到的I/O写入操作写入源缓存
② 将I/O传输到目标缓存
③ 目标确认
④ 主机提交I/O写入完成
5.2. SRDF/Metro写模式
在传统的SRDF模式下,远端的存储是处于只读模式。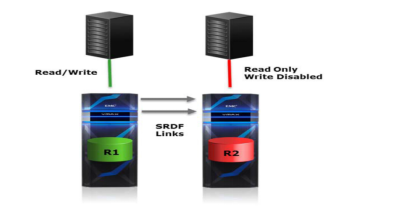
SRDF/Metro对此状态进行改进,使得 远端存储(R2)device拥有和生产存储(R1)device拥有一样的特性(geometry, device WWN, and so on)并开启R2 device的写功能。进而呈现给主机,实现存储的高可用和双活特性。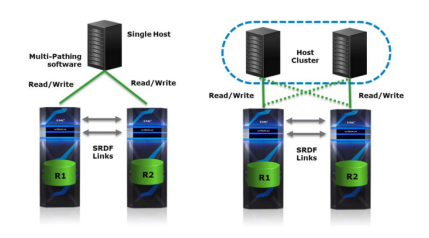
5.3. 仲裁
由于SRDF/METRO要实现active/active的功能,因此,需要VMAX自己来协调写冲突。Dell EMC采用两种机制来防止脑裂。bias(偏好)机制和witness/quorum(见证/仲裁)机制。
BIAS机制比较简单。也就是事先确定好如果系统故障由那个阵列来接管业务。VMAX在刚开始创建SRDF/METRO组的时候,这个时候R1是bias设备,当系统进入ACTIVE-ACTIVE状态后,用户可以修改bias设备。如果SRDF链路出现故障,bias设备将接管业务,no-bias设备将停止提供服务。系统进入Paritioned或者Suspended状态。如果是非集群方式,主机多路径软件将切换到bias设备(如采用了交叉连接的方式),系统可以继续运行。如果是集群方式,只有bias站点的主机可以访问,另外一个站点的主机停止访问。由集群软件来处理客户端的切换,系统可以继续提供服务。
bias机制太简单,可能造成存活的站点和bias存储不一致的情况,这样系统的业务连续性无法得到保障。这个道理很简单,比如你把R1设为bias,但R1站点出了问题,R2由于不是bias设备而不能接管业务,造成业务中断。为了解决这个问题,必须采用第三方站点见证/仲裁的方式。目前,SRDF/METRO支持采用额外的一台VMAX3做仲裁或者虚拟的仲裁机做仲裁。
5.4. 是否交叉连接
双活架构下,两个数据中心均可提供服务,那么数据中心A的机器可以通过SAN访问数据中心B,数据中心B的机器也可以通过SAN访问数据中心B。在与供应商在方案交流中,有的厂商会推荐使用交叉连接,有的不建议使用交叉连接,两种连接方式各有利弊。在交叉连接时,需要在操作系统层面上控制IO不跨中心访问,部分厂商的实现会有所不同。在本数据中心发生链路或者存储故障时,可以跨中心访问另外一个数据中心的存储,这样的好处是数据库主机除了性能降低,不会出现切换,坏处是性能会下降。但是通常存储出现故障,已经是大面积故障,而且我们并没有将操作系统和数据库数据库盘完全分开,存储故障必然会导致数据库的操作系统故障,所以我们的建设方案是不进行交叉连接。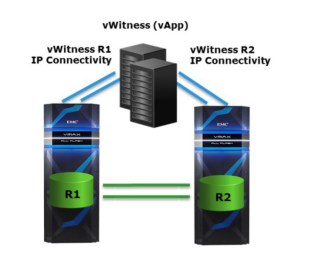
6. 可靠性测试
测试是检验方案是否完善的唯一标准,经过系统的测试,覆盖可能的各种故障场景,是方案可以顺利上线的保证。各个存储、交换机、波分、链路均有冗余,仲裁在不出现脑裂时无需参与。所以单个中间设备故障,不会导致异常。
| 场景 | 存储1 | 存储2 | 备注 | |
| 1 | 存储1 到 仲裁 中断 | √ | √ | |
| 2 | 存储2 到 仲裁 中断 | √ | √ | |
| 3 | 存储1到 存储2中断 | √ | × | 设置存储1优先 |
| 4 | 存储1 故障 | × | √ | |
| 5 | 存储2 故障 | √ | × | |
| 6 | 仲裁故障 | √ | √ | 进入BIAS模式 |
| 7 | 仲裁到存储1中断仲裁到存储2中断 | √ | √ | 进入BIAS模式 |
| 8 | 存储1到存储2中断仲裁故障 | × | × | 存储之间中断、且仲裁无法通信,存储均不能访问 |
| 9 | 存储1到存储2中断存储2到仲裁中端 | √ | × | 存储1仲裁胜出 |
| 10 | 存储1到存储2中断存储1到仲裁中端 | × | √ | 存储2仲裁胜出 |
| 11 | 存储1故障存储2到仲裁中端 | × | × | 与场景8类似存储均不能访问 |
| 12 | 存储2故障存储1到仲裁中端 | × | × | 与场景8类似存储均不能访问 |
| 13 | 存储1故障仲裁故障 | × | × | 与场景8类似存储均不能访问 |
| 14 | 存储2故障仲裁故障 | × | × | 与场景8类似存储均不能访问 |
| 15 | 存储1到存储2中断存储1 到仲裁中端存储2 到仲裁中端 | × | × | 与场景8类似存储均不能访问 |
总结就是2台存储之间通信故障,或者有一台存储故障,则必须有一个存储(另外1台存储)能与仲裁通信,否则就会出现脑裂。
在存储存储符合预期后,进行带业务的测试,也是非常有必要。项目中我们在所有业务上线前,进行了全业务的带压力的可靠性测试,在全部测试结构符合预期后,项目才符合上线条件。具体测试包括以下几方面:
1、 关键SAN网络设备的故障
2、 关键SAN网络的链路故障
3、 关键SAN网络光模块故障
4、 波分链路故障
5、 存储控制器故障
6、 关键网络设备的故障
7、 关键网络设备的链路故障
8、 关键网络设备的光模块故障
9、 各个系统数据库主机部分故障
10、 各个系统应用主机部分故障
7. 延时的应对
双活数据中心的架构下,两个数据中心距离40km以上,本身就有较大的固有延时,如果运营商链路抖动,会造成IO延时加大,极端情况下会造成Oracle RAC的脑裂。最重要的是,延时属于不可控因素。通常链路故障不仅会影响SAN链路,同样会影响网络,所以我们的做法是关闭整个数据中心,切换为单数据中心运行。待故障恢复后再恢复为双活数据中心运行。通常情况下是保证数据中心A正常运行,切断数据中心B。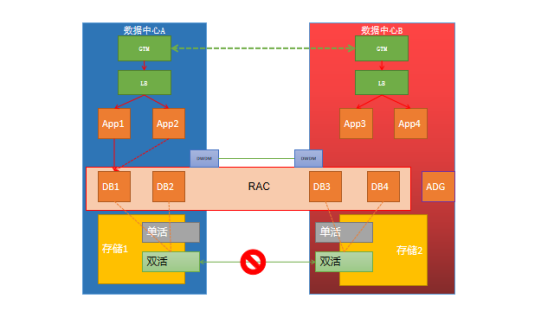
如果数据中心A出现严重问题,手动切换到数据中心B。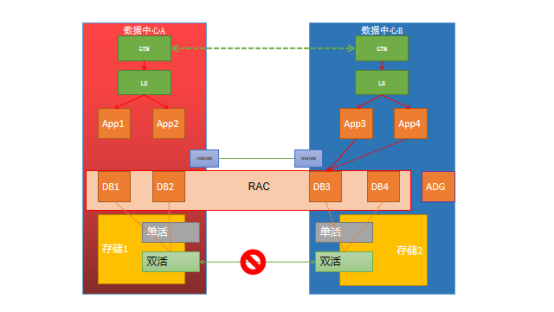
切换过程:
1、 通过GTM屏蔽一个数据中心的记录
2、 通过自动化脚本关闭部分未通过DNS访问的遗留系统
3、 检查仲裁状态,切断SAN网路
4、 如果RAC出现严重故障,则停用RAC,转移到ADG提供服务。
8. 运维监控
我行在多年前就建立了以Tivoli为基础的监控平台,在操作系统、网络、数据库等方面的监控表现还可以。但是在存储的监控上,就有些力不从心,存在诸多难点难以解决:
- 厂商多、型号多、类型多
- 管理方式种类繁多
- SMI-S实现各不相同
- 部分逻辑概念并不一致
- 仲裁类特殊组件无法监控
SAN网络监控困难
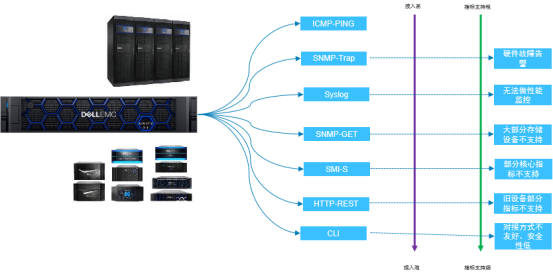
存储承载着最核心的业务,存储 的 监控 却一直 处于 空白 的状态, 基本靠人肉巡检。 缺少集中化的,统一的存储专业性管理平台。建立存储的集中运维管理势在必行,关系着业务稳定运行和业务的连续性。同时,我们期望存储部分的监控能够和网络的监控、以及计算资源、应用能够打通,未来能够形成由下至上的立体化、集中化、一体化的全方位、集中化的监控解决方案。当前并没有很好的商业软件可以解决以上的问题,所以我们选择了Dell EMC的开源解决方案PowerOPS。以存储为突破点,逐渐将系统、网络等都迁移到开源监控平台 ,逐步形成一个开源、开放、稳定、融合创新型的下一代运维管理解决方案。
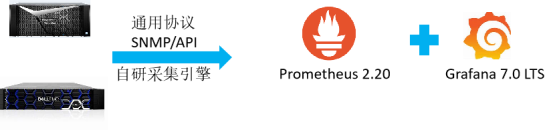
PowerOPS主要是通过存储设备提供的REST API来采集存储的metrics,由prometheus采集到时序数据库中,使用Grafana来展示监控数据,同时使用prometheus的alertmanager来发送告警。 此解决方案核心为自研采集引擎exporter(包括多种厂商多种型号的定制开发)、定制化的告警规则和告警方式。 通过实时收集Dell EMC硬件产品基础的配置、容量、性能、事件数据至方案平台,实现Dell EMC产品的硬件、容量、性能实时告警。此方案轻量,稳定,实施周期短。Dell EMC提供Prometheus &Grafana优化后的高性能开源平台。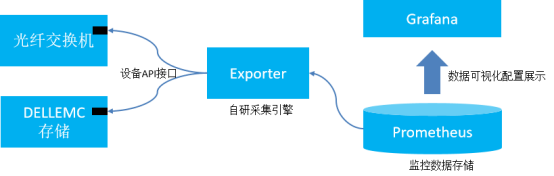
对于Dell EMC存储,通过设备的REST API,实现存储基础配置、容量、性能数据和PowerOps方案平台实现监控对接。对于光纤交换机,通过设备的REST API实现交换机设备级别CPU,内存,端口状态、流量等基础信息,以及CRC ERROR,光衰等核心指标监控对接。
9. 总结
目前主流的双活数据中心架构,基本上有两个发展方向,分布式架构和传统存储双活复制的架构。银行作为金融行业,稳定压倒一切,且没有过多人力和精力去研究新的技术和方案,所以选择存储双活的架构是比较稳妥和安全的选择。Dell EMC存储的双活解决方案在业内已经有很多案例,包括我们自己也使用了vplex很多年,对其功能和稳定性比较有信心。在双活数据中心的建设中,主要是解决了以下几个问题:
1、 哪些系统可以做双活?
绝大部分应用的主机之间并没有关联,共享数据一般存放在数据库或者是NAS存储上。SAN存储和NAS存储双活可以解决数据共享的问题,所以绝大部分应用都可以直接做双活。
2、 数据中心如何切换?
当前银行的系统多达几百个,建设周期长达十几年,在不同时期架构、基线、标准、基础环境、硬件等各不相同。虽然新的系统是基于双活架构的,但是在双活切换时,如何保证那些老的系统可以正常使用,是一项十分庞大的系统工程。我们在梳理完所有系统后,针对每种系统分别制定切换方案,并通过自动化运维工具,实现一键切换。
3、 要不要切换?
当故障发生时,何种故障、多大面积的故障、多大影响的故障需要进行数据中心切换,切换是否比不切好,都是一个难以抉择的问题。通常做法是尽量多的模拟各种场景,根据不同场景下的影响来评估影响,根据影响来决定是否切换,做好预案。
4、 如何知道能不能切换?
根据存储切换的测试场景可以看出,如果切换时出现了存储的脑裂,将会出现两个数据中心均不可用。所以仲裁是否正常,决定了存储切换是否成功,所以对于仲裁的监控尤为重要。常见的监控软件并不能对仲裁进行监控,所以我们选择了Dell EMC的开源解决方案PowerOPS。能够实时监控仲裁的状态,确保能够正确的切换。
我们当前的双活架构还存在很多问题,比如数据库双活并没有起到真正双活的作用,这主要受到数据库软件的稳定性、软件架构、工期等原因影响。由于双活存储复制本身是稳定成熟的技术,基于这种架构,后期这些问题后期都可以逐步进行完善。
作者简介:潘猛 成都农商银行系统工程师,从业 18 年。在网络、 存储、系统、云计算等领域都有 10 年以上工作经验,熟悉数据库、 大数据、Python、Zabbix、Ansible 等。目前主要从事项目管理、方 案设计、产品选型、POC 测试等运维工作。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞12
添加新评论8 条评论
2022-04-28 10:45
2022-04-06 16:41
2021-11-09 10:17
2021-05-31 21:13
2021-05-08 14:51
2021-04-29 18:51
2021-04-25 15:15
2021-04-25 14:58